《表3 Stanford Dogs数据集下不同算法分类精度对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
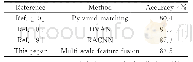
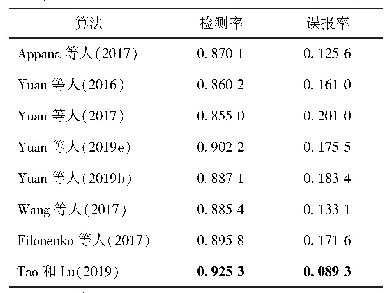
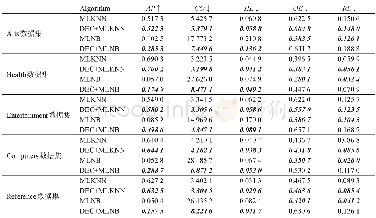
进一步在两个数据集上对多尺度特征融合算法和其他文献算法的分类精度进行对比,对比结果如表3和表4所示。从表3可以看出,在Stanford Dogs数据集上,本文算法的分类精度均高于DVAN(diversified visual attention networks)与多尺度金字塔匹配算法,但与RACNN(recurrent attention convolutional neural network)算法相比还有一定的差距。但是RACNN的结构包含三个尺度的子网络,每个子网络又包含了分类与APN(attention proposal sub-network)两种类型的网络,使得相应区域的特征提取需要经过多步实现,计算量较大,并且RACNN一次只能定位一个关键区域,但在真实场景中人类视觉分辨时往往是多个关键点共同作用;分析表4结果可知,文献[11]使用了目标边界框、关键点标注等人工注释,其检测精度明显低于其他方法,这是由于人工标注的关键特征点是固定的,而不同网络在学习过程中对判别区域的关注位置可能会发生变化。文献[14]同时使用了两个卷积神经网络提取特征,其输出经过外积相乘,池化后获得结合特征,本文方法对于局部模型不需要使用额外神经网络且定位更加精确,其分类精度比B-CNN算法提高1.6%。文献[9]的训练需要经过多次迭代,本文方法的训练只需一个阶段,且分类精度比文献[9]略高0.4%。
| 图表编号 | XD00149532300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.25 |
| 作者 | 李思瑶、刘宇红、张荣芬 |
| 绘制单位 | 贵州大学大数据与信息工程学院、贵州大学大数据与信息工程学院、贵州大学大数据与信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}