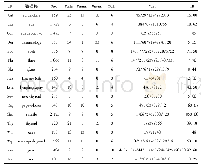
《表2 各模型的分类精度:不均衡数据集下基于CNN的中图分类标引方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
(注:精度的取值均为四舍五入法保留两位小数,后续处理仍采用相同的方法,不再重复说明。)
在通过交叉验证网格搜索调参后,确定NB、LR、KNN、SVM的最佳参数。以NB、LR、KNN、SVM作为基分类模型,以卷积核长度为2的TextCNN作为融合分类模型进行分类模型的训练。需要说明的是,TextCNN本质上也是使用了二维卷积核,只是其宽度固定为输入数据的长度,对于本实验来说相当于使用大小为(2,21)的卷积核,其中21为类目数。同时,对类概率分布求平均并将其作为朴素贝叶斯的输入,以此作为基线模型。不同基分类模型、基线模型和融合模型在各个类上的分类精度及平均精度如表2所示。可以看出,基分类模型中,NB、LR、KNN、SVM分别在6、7、4、5个类别上取得最佳效果(其中,KNN和SVM对G48类的分类精度相同)。使用融合模型后,相比于基分类模型的最佳性能,总体分类精度有了6%的绝对提升、11%的相对提升。其中,G42、G61、G71、G51、G75、G45、G48、G76、G40共计9个类的分类精度均高于基分类模型,其他类的分类精度则介于基分类模型的最佳性能与最坏性能之间。相比于基线模型平均0.41的分类精度,融合模型的总体分类精度有了19%的绝对提升。基线模型的总体分类精度低于所有基分类模型,且有明显偏向于大类的倾向,在G64、G63、G61上的分类精度高于80%,部分优于本文方法的效果;而在少数类上的分类精度却接近或等于0,远不及本文所提方法的效果,这说明本文方法是有效的。
| 图表编号 | XD00157144700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.25 |
| 作者 | 冉亚鑫 |
| 绘制单位 | 中国科学技术信息研究所、富媒体数字出版内容组织与知识服务重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}