《表3 Stanford Dogs数据集上的mAP(%)比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
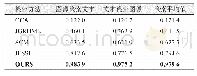
因为CIFAR-100(32×32)数据集比CaffeNet(227×227)和VGGNet(224×224)两个网络模型的输入尺寸要小很多,如果增大CIFAR-100中的图像尺寸,会导致图像模糊不清,在一定程度上给实验结果带来影响。所以,本文选择了另外一个数据集Stanford Dogs用来验证本文方法在CaffeNet和VGGNet网络模型上性能。表3中展示了Stanford Dogs数据集利用本文方法在CaffeNet和VGGNet两个网络上的实验结果。由表3的实验结果可以看出,在CaffeNet网络模型上,本文的方法均比文献[16]中的单个CaffeNet网络模型和双流网络模型DNC的分类精度要高,分别高了2.30%,1.20%。同时,在VGGNet网络模型上,本文的方法分别比文献[16]中的单个VGGNet高了5.76%,2.31%。实验结果表明,本文提出的方法比文献[16]中的双流卷积神经网络模型分类精度更高,具有较好的分类性能。
| 图表编号 | XD00170281400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.16 |
| 作者 | 罗会兰、易慧 |
| 绘制单位 | 江西理工大学信息工程学院、江西理工大学信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}