《表2 不同方法在NUS-WIDE数据集上的MAP值》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
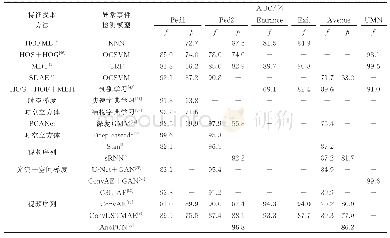
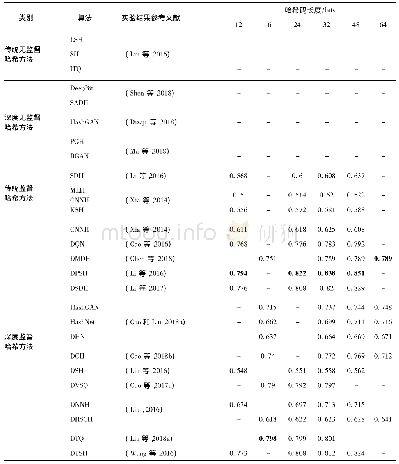
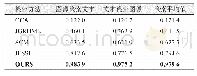
通过上述实验结果对比可以看出本文方法在三个数据集上都取得了较好的结果。在Wiki数据集上的MAP平均值相对于CCA、JGRHML、SCM和JFSSL等方法,分别提高了0.191 4、0.163 7、0.111 3、0.144 3;在NUS-WIDE数据集上分别提高了0.280 0、0.165 5、0.147 7、0.091 0;在XMedia数据集上分别提高了0.858 2、0.568 1、0.352 3、0.185 0。通过对比分析可以发现,仅考虑跨模态低阶底层特征相关性的CCA方法,检索效率较低。跨模态数据之间最大的关联是语义关联,尤其在数据特征差别大,维度差异较明显时检索效率更低。利用数据的语义标注信息进行子空间构造,能够挖掘跨模态数据的高阶相关性,相对CCA而言,SCM、JGRHML、JFSSL等都取得了较好的结果。进一步对比发现,将数据语义标注信息和公共子空间稀疏结构特征结合在一起的JFSSL效果较好。JFSSL在利用语义标注信息时直接采用语义标注的分类信息,在跨模态数据相关性方面仍有提升空间。基于此,本文对跨模态数据的语义标注进行相关性处理,提取高阶语义相关特征,因此在进行子空间映射时投影效果更好,而且模型复杂度更低,跨模态检索精度更高。
| 图表编号 | XD00174900200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.25 |
| 作者 | 朱路、田晓梦、曹赛男、刘媛媛 |
| 绘制单位 | 华东交通大学信息工程学院、华东交通大学信息工程学院、华东交通大学信息工程学院、华东交通大学信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}