《表2 在NUS-WIDE数据集上的平均均匀准确率值》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
%
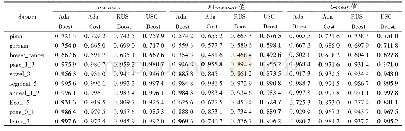
局部敏感哈希[5](LSH)随机生成线性映射函数,训练过程不依赖于数据集,近邻检索性能不能随着编码长度的增加而显著提升,且本文所采用的均是紧凑二值编码,故而局部敏感哈希[5]的近邻检索性能相对较弱。锚图哈希[7](AGH)采用K均值算法学习数据集的锚点,并通过分割锚点之间的相似性谱图生成数据集的二值编码,以确保相似数据点被映射为相同编码,其近邻检索性能优于局部敏感哈希算法。锚图哈希要求数据集服从于均匀分布,而本文所采用的真实数据集并不符合均匀分布,故而锚图哈希的近邻检索性能仍相对较弱。迭代量化(ITQ)哈希[8]、K均值哈希[9](KMH)、铰链哈希[11](RSH)、序列约束哈希[1](OCH)以及模糊序列感知哈希(ARPH)不再要求训练数据满足特定的分布特性,近邻检索性能优于锚图哈希。迭代量化哈希[8]将相似或相近的数据点映射至同一个正立方体顶点,并赋予相同的二值编码。在迭代量化哈希算法中,正立方体的顶点是固定的,对数据集分布特性的自适应能力较弱。相对而言,K均值哈希[9](KMH)学习能够同时最小化相似性误差和量化误差的顶点,使得编码中心点与数据集的分布特性相符,故K均值哈希的近邻检索性能要优于迭代量化哈希。K均值哈希[9]、迭代量化哈希[8]、锚图哈希[7]以及局部敏感哈希[5]只关注数据点之间的相似性保持问题,而近邻检索算法更重视数据点之间的相对相似性。铰链损失哈希[11]建立了基于三元组之间的相对相似性保持约束条件,序列约束保持哈希[1]建立了基于四元组之间的相对相似性保持约束条件。模糊序列感知哈希建立了类似于均匀准确率的目标,要求在每一个截断k处,在汉明空间与欧式空间内得到的近邻检索结果是相同的,其属于序列保持约束。从而可知,铰链损失哈希[11]、序列约束保持哈希[1]以及模糊序列感知哈希关注如何保持数据点之间的序列关系,更适应于近邻检索任务,性能相对较优。但是,铰链损失哈希与序列约束保持哈希未关注近邻检索中的模糊序列问题,对于与查询数据点具有相同汉明距离的数据点,采用随机排序的规则,使得算法性能的稳定性较差。模糊序列感知哈希定义了首位区分规则,并学习满足这一规则的序列保持二值编码,从而可有效区分近邻检索中的模糊序列,算法性能较稳定。在三种大型图像数据集上的近邻检索实验也证明了,模糊序列感知哈希具有较优的近邻检索性能。
| 图表编号 | XD00222628600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.01 |
| 作者 | 王振、孙福振、张龙波、王雷 |
| 绘制单位 | 山东理工大学计算机科学与技术学院、山东理工大学计算机科学与技术学院、山东理工大学计算机科学与技术学院、山东理工大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}