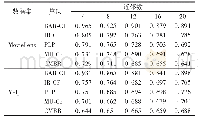
《表1 两个数据集上各种算法在不同近邻个数下的平均绝对差》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文把基于二部网络划分的标签传递社区挖掘推荐算法(CMBR)与其他4种算法的预测结果准确度和平均绝对差进行比较。这4个算法分别是基于双向关联规则项目评分预测的推荐算法(Collaborative Filtering recommendation algorithm based on item rating prediction using Bidirectional Association Rules,BAR-CF)[27]、基于项目评分预测的推荐算法(Collaborative Filtering recommendation algorithm based on Item Rating prediction,IR-CF)[28]、基于网络链接预测的用户偏好预测方法(user Preferences prediction method based on network Link Prediction,PLP)[29]和改进的基于用户的协同过滤的方法(Modified User-based Collaborative Filtering,MU-CF)[30]。从数据集中,观察到用户评论的条数的分布大部分集中在4~20,也就是说用户侧顶点的近邻个数集中在4~20。为了测试在各种近邻个数下不同算法的结果的平均绝对差,本文在实验中对4~20、间隔为4的不同近邻数进行测试。实验结果如表1所示。
| 图表编号 | XD00222676200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.10 |
| 作者 | 盛俊、李斌、陈崚 |
| 绘制单位 | 扬州大学信息工程学院、扬州市职业大学信息工程学院、扬州大学信息工程学院、扬州大学信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}