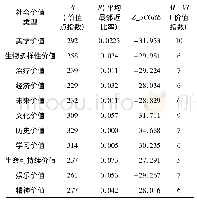
《表1 各社会支持类型帖子示例》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《在线健康社区中用户社会支持交换行为的跨文化比较研究》
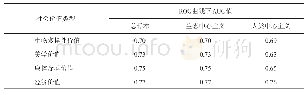
在之前的研究中[46],我们基于帖子文本特征构建分类模型,在社会支持的识别训练上取得了良好的效果。考虑到近两年来深度学习方法在文本挖掘中的高效发展,本研究引入词袋模型(BOW)和Word2Vec(W2V)[47]构建新的文本特征集用于构建分类模型,见表2。本研究利用逻辑回归、支持向量机、朴素贝叶斯、K近邻、决策树、随机森林、Ada Boost多种算法和不同特征集进行组合,对训练集数据进行训练和评估,通过十折交叉验证并使用加权F1得分和加权AUC评估分类模型的性能。表3给出模型训练后精度最好的算法和特征集的组合,更多模型训练细节及结果对比方式可参考WANG et al.[46]的研究,最终选取分类效果最好的训练模型并应用于所有未标记的数据。表4给出分类运行结果,即社会支持内容在在线健康社区中的分布。值得注意的是,并不是所有帖子都包含社会支持,如一些广告帖、灌水帖等。在USOHC中,不包含社会支持内容的帖子有1 339 144个,在CNOHC中相应内容的帖子为49 800个。
| 图表编号 | XD00162026500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.20 |
| 作者 | 王熙、佟星、郑博雯、朱渝珊、谭天一、曾钰琪、李惠 |
| 绘制单位 | 中央财经大学信息学院、乔治梅森大学人文与社会科学学院、清华大学经济管理学院、中央财经大学信息学院、中央财经大学信息学院、中央财经大学信息学院、中央财经大学信息学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}