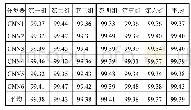
《表3 基分类器分组训练后在测试集上的准确率对比(单位:%)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
对于同一个基分类器,由于每一组的训练数据不完全相同,所以经过不同的分组训练后在测试集上的表现也存在差异。但是从单个基分类器的所有分组训练过程的角度来看,原始训练数据集中的每个样本被均参与了训练,因此基分类器的训练充分利用了原始训练数据集,而且降低了模型训练对于验证集选取的依赖性。从表3可以看出,不同的数据集使用方法和不同的网络结构都会对实验结果产生影响,在这两者的影响下产生了stacking第二阶段学习的训练数据和测试数据,并且36个模型训练结果在测试集上得到了99.39%的平均预测准确率、99.48%的最高预测准确率和99.31%的最低预测准确率。之后,选取不同的分类器作为stacking第二阶段学习分类器,进行对比实验,最后在测试数据上得到的准确率如下:
| 图表编号 | XD00158311600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.01 |
| 作者 | 陈庭轩、陈文敏、王正阳 |
| 绘制单位 | 华中师范大学物理科学与技术学院、华中师范大学物理科学与技术学院、华中师范大学物理科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}