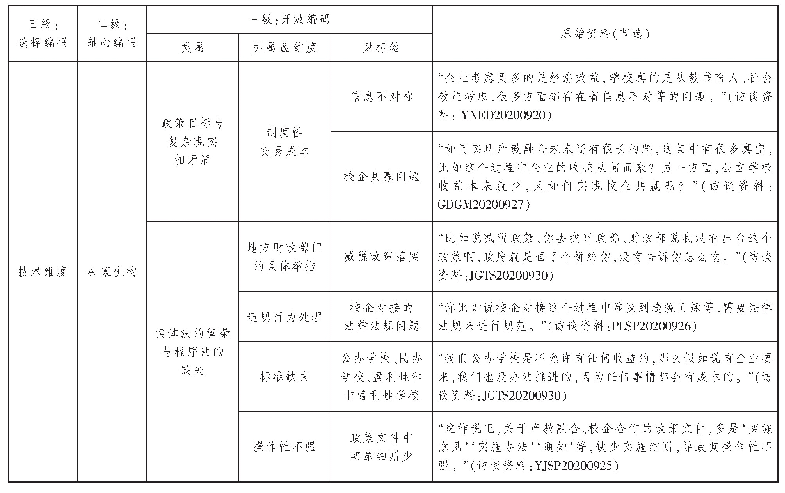
《表1 访谈资料的编码分析过程》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文的数据分析主要通过3个层次的质性资料编码分析来完成[29]。第一层的编码首先把文本资料打散后,根据受访对象所陈述的语义进行合适的标注,并按照其搜寻信息的对象进行分类和统计,例如把受访者因为每个月只能见到女儿一次,为了了解女儿在学校的情况,有时候会联系班主任老师询问女儿在学校的情况标注为“子女教育”,把搜寻信息的来源或对象标注为“教师”并记录其在文本中出现的频次;第二层次的编码根据标注间的关联,将其划分为相对独立的主题,例如将“子女教育”“集体关注”等标准划分为“情境契合”;第三层次的编码根据第二层次划分出主题之间的关联聚类成相对独立的类别,例如根据主题之间的关联,把“风俗文化、宗教信仰、族群规则、族群知识”等都归属到“传统习俗”这个类别,然后再根据这些类别中EMSP搜寻信息的来源和对象,将EMSP的信息搜寻分为两类,一类为跨越族群的信息搜寻,另一类为族群内部的信息搜寻。根据上述过程对收集到的资料进行语料分解和语义比较,得到412条标注,在此基础上剔除无法归类或表征意义与本研究相关度不高的标注57条,并将其划分为14个主题,根据主题之间的关系将其聚类成5个相对独立的类别,并划分为两种不同类型的信息搜寻(见表1)。
| 图表编号 | XD00156115500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.15 |
| 作者 | 朱明、刘宇 |
| 绘制单位 | 云南大学历史与档案学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}