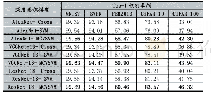
《表4 各模型在CNLI数据集上的混淆矩阵》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
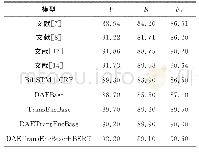
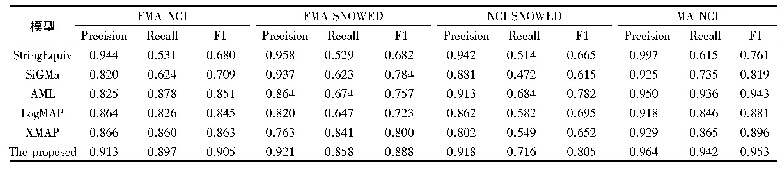
使用CNLI数据集上训练出来的模型,针对NTCIR-9RITE数据集,本文将训练集、验证集和测试集合并,一共1221条数据全部作为测试集。该模型在NTCIR-9RITE数据集上的准确率为67.63%,而SVM模型则选择976条数据作为训练集,245条数据作为测试集,最后SVM模型在245条数据上的准确率为62.44%。见表5。表6为多层注意力模型在NTCIR-9RITE数据集的混淆矩阵。其中列为预测类别,行为真实类别。从表6可以看出,用CNLI上训练好的模型可以很好识别出NTCIR-9RITE数据集上的蕴涵关系,而矛盾关系和独立关系识别效果不太好。这也说明该模型在其它中文文本蕴涵数据集上也是有效的。
| 图表编号 | XD00154279800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.16 |
| 作者 | 严明、刘茂福、胡慧君 |
| 绘制单位 | 武汉科技大学计算机科学与技术学院、武汉科技大学智能信息处理与实时工业系统湖北省重点实验室、武汉科技大学计算机科学与技术学院、武汉科技大学智能信息处理与实时工业系统湖北省重点实验室、武汉科技大学计算机科学与技术学院、武汉科技大学智能信息处理与实时工业系统湖北省重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}