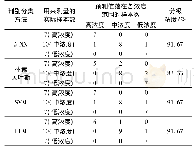
《表1 不同判别分类方法模型预测结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
所有光谱数据在分析之前都进行了预处理,首先采用多元散射矫正(multiple scatter correction,MSC)消除光谱曲线的基线漂移,使不同样本之间的光谱差异变得明显,之后进行归一化数据处理,将矩阵的每一行压缩到[-1,1]。归一化的目的是使预处理的数据被限定在一定的范围内,从而消除奇异样本数据导致的不良影响。将样本按照浓度不同分为高浓度(300~400 mg/kg)、中浓度(100~300 mg/kg)、低浓度(小于100 mg/kg)三个组别进行试验。表1所示是不同判别分类方法模型预测结果。
| 图表编号 | XD00145316300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.01 |
| 作者 | 陈菁菁 |
| 绘制单位 | 北京信息科技大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}