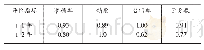
《表1 模型预测效果比较:朴素贝叶斯算法与车辆风险分类》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:()内数值为预测样本数占行样本数的百分比,如0.84=417/480。
为验证建立模型的拟合效果,首先利用caret包中函数createDataPartition将提取的数据拆分成两部分,一部分为训练数据,一部分为检验数据,分别占总样本量的75%和25%,即ntrn=2 110,ntst=702,且训练数据中索赔占31.7%,检验数据中索赔占31.6%。基于训练数据,朴素贝叶斯算法使用caret包中train函数,建立一个概率模型,利用该模型对检验数据进行预测分析,Logistic回归模型是基于R中glm[10]函数建立的,两种分类方法的分类效果如表1所示。检验数据样本量为702,发生索赔的有222个,无索赔的有480个。
| 图表编号 | XD00144929100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.28 |
| 作者 | 郭念国 |
| 绘制单位 | 河南工业大学理学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}