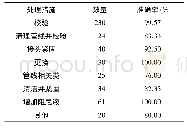
《表4 朴素贝叶斯分类法与类中心向量法的实验比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于类中心向量的论文作者归属机构自动识别方法研究》
在作者归属机构自动识别问题上,本文将类中心向量法与传统的朴素贝叶斯分类法进行了对比分析。朴素贝叶斯分类法是常用的文本分类方法之一,本文在词包(bag of words)的基础上使用贝努利模型(Bernoulli model)建立了朴素贝叶斯分类器,使用该分类器对英文作者地址信息进行分类。当训练数据全部为中科院的作者地址信息,测试数据中同时含有中科院与非中科院的作者地址信息时,该方法理论上无法对测试数据中的非中科院作者地址信息进行有效识别。因此在实验中,设置为如果测试数据中的某个作者地址中的词与训练集中的词重叠比例没有超过该地址中词总数的40%时(此数值通过比较实验获得),判断该作者地址为非中科院机构。朴素贝叶斯分类法的实验结果如表4所示,从中可以发现,在此问题上类中心向量的方法一定程度上优于朴素贝叶斯的方法,这主要是由于类中心向量法依据英文作者地址信息的特点进行了有针对性的设计所导致的。与基于类中心向量的方法相比较,传统朴素贝叶斯分类法使用词包而不是文字块,使用英文作者地址信息中的全部词而不是位置靠前的词,这些都给朴素贝叶斯模型引入了过多的数据噪音,导致了该方法的实验效果不够理想。
| 图表编号 | XD0072257300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.24 |
| 作者 | 何涛、王桂芳、马廷灿 |
| 绘制单位 | 中国科学院武汉文献情报中心、中国科学院武汉文献情报中心、中国科学院武汉文献情报中心 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}