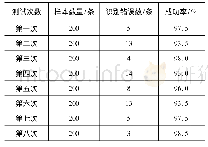
《表2 LSTM与朴素贝叶斯的文本分类结果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于多模态投资者情绪数据的USD/CNY汇率波动率预测研究》
注:由于部慧等(2018)并未直接给出总体的正确率,这里取其三分类精度的平均值作为指标。
LSTM训练过程如图5所示。从训练曲线可以看出三分类模型在训练集中得到了很好的拟合。损失值不断下降,正确率在迭代2 000~3 000次左右就已经达到了100%。训练出的模型在测试集中表现也比较优异,由于本文是三分类,所以采用模型评价标准的平均值,也就是先计算acuracy、recall、F的指标取平均数AVA、AVR、AVF作为评价指标,整体准确率平均为86.79%,表明模型不存在过拟合现象。本文采用朴素贝叶斯共同实验进行对比,对比实验用同样的中文文档作为语料库,对语料库预处理、利用word2vec转换成词向量,再用朴素贝叶斯构建文本分类模型,实验以整体平均正确率来作为精度评价指标,如表2所示。同时,表2中还列出了具有代表性的前期文献所得到的朴素贝叶斯分类结果(包括中文文档与英文文档分类)。结果表明,无论是本文的朴素贝叶斯方法还是前人研究中的朴素贝叶斯方法,在文本分类精度的各个评价指标上都低于LSTM模型。因此,运用LSTM所分类出来的文本,可以更有效地判断文档中的语义信息,更贴近真实的投资者情感倾向。
| 图表编号 | XD00198048500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.31 |
| 作者 | 汪文隽、王亦天、操玮、任思儒 |
| 绘制单位 | 合肥工业大学经济学院、合肥工业大学经济学院、合肥工业大学经济学院、合肥工业大学经济学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}