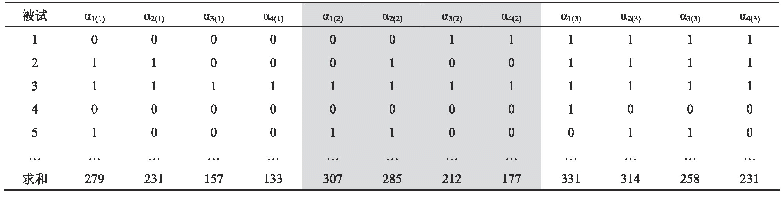
《表4 3道多属性题目的参数估计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《混合模型在英语听力诊断测评中的应用——基于Mixed-CDMs与G-DINA模型的对比分析》
注:Est.=估计值;S.E.=标准误;“1”表示掌握了该属性、“0”表示未掌握该属性,如P(10)表示掌握了该题所测第一个属性的答对概率,而P(01)表示掌握了该题所测第二个属性的答对概率。
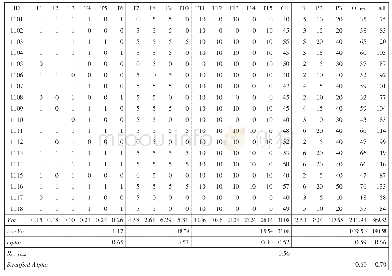
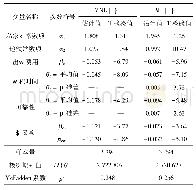
本研究对多属性题目进行参数估计,其中3道题目的结果如表4所示,可以看出:每个估计值都有一个标准误(S.E.),其中Mixed-CDMs的S.E.均值为0.03,且在0.01~0.09区间,相较于G-DINA模型(S.E.均值为0.07,在0.03~0.18区间)有所降低,说明混合模型题目参数估计的准确性比G-DINA模型有所提高。值得注意的是,G-DINA模型中3道题目的参数估计值出现了排斥现象:Item 3的2个属性(A2词汇、A4细节)表现为相互排斥,即同时掌握这2个属性时,答对概率(0.85)并未递增,反而低于单独掌握A2(0.99)或A4(0.86)的答对概率。根据现有语言学及二语习得理论,这种属性之间的排斥现象难以解释。而在Mixed-CDMs中,Item 3的这2个属性不存在排斥现象,而为互补关系——究其原因,可能在于Item 3选用的是补偿模型DINO,使得属性之间的关系更加直观易读。此外,在G-DINA模型中掌握单个属性(A2或A4)对Item 4的答对概率远低于不掌握任何属性(猜测)的答对概率,这种现象也较难解释;相似的现象同样出现在Item 16的2个属性(A3句法、A5主旨)中。而在Mixed-CDMs中以上难解的问题都得到了消解,且更易解读,即Item 4、Item 16的猜测概率不会高于单个属性的答对概率,且两个属性具有协同作用。
| 图表编号 | XD00140735500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.01 |
| 作者 | 董艳云、马晓梅、孟亚茹 |
| 绘制单位 | 西安交通大学外国语学院、西安交通大学外国语学院、西安交通大学外国语学院 |
| 更多格式 | 高清、无水印(增值服务) |

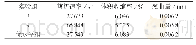

{kind=link}