《表1 测试数据分布:不完整高维大数据的相似度度量方法研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了测试本文方法在实现不完整高维大数据相似度度量和特征提取中的应用性能,结合MAT-LAB进行仿真实验,不完整高维大数据库采用Credit Approval 200G数据库模拟,对数据采样的规模为2000,数值属性的个数为12,不同属性值的数目为2,相异性度量值为0.24,不完整高维大数据的每个数据对象由21个语义本体属性和1个数值属性描述,测试数据分布集见表1。
| 图表编号 | XD00140355400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.01 |
| 作者 | 漆世钱 |
| 绘制单位 | 武警海警学院 |
| 更多格式 | 高清、无水印(增值服务) |




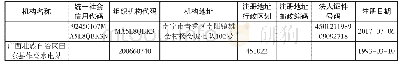

{kind=link}