《表3 变量限:Spark环境下不完整数据集成填充方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
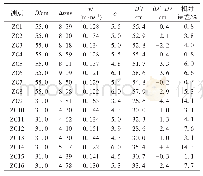
为了全面控制本文使用的数据库中的缺失值,本文选择的所有实验数据集均为没有缺失记录的完整数据集.为了评估本文所提模型对不完整数据集填充问题的有效性及对大数据处理的有效性,采用了Abalone、KDD99[12]和URL Reputation[13]等3个数据集,每个数据集都同时包含连续型和分类型特征属性.表2列举了上述数据集的实例个数和属性个数.
| 图表编号 | XD00212238200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.01 |
| 作者 | 邹萌萍、彭敦陆 |
| 绘制单位 | 上海理工大学光电信息与计算机工程学院、上海理工大学光电信息与计算机工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}