《表1 link=1时不完整公交IC卡数据集填充误差统计值分布》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于改进k~*-means算法的不完整公交到站时间填充》
同样,对比分析LR、KNNI算法的填充性能.这2类方法均未借助历史站点间出行表,仅采用当前单趟公交的出行信息,对缺失到站时间进行填充.由表1、2和图4、5可知,当link=1或link=-1时,基于LR算法的已知到站时间的平均填充误差在250~450 s的范围内波动,且可信度的波动性也相对较高(link=1时,RMSE平均值为 (287±55)s,MAPE平均值为12±2;link=-1时,RMSE平均值为(378±91)s,MAPE平均值为19±5) ,仅劣于kmeans算法的填充效果.同时,基于拟合插值思想的LR算法仅在少量完整数据对象存在的前提下,无法拟合出实时变化的参数来反映单趟公交运行过程的时空变化特性,因此,填充误差相对较大.而基于近邻填充思想的KNNI算法能够利用少量真实的到站时间来近邻填充缺失的到站时间,填充精度稍优于LR算法填充的误差精度.由此可见,在数据完整的情况下,基于近邻填充的思想能够有效反映数据中的局部运行特性,取得较好的填充效果.
| 图表编号 | XD002552100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.01.10 |
| 作者 | 赵霞、张勇、尹宝才、刘浩、张可 |
| 绘制单位 | 北京工业大学北京市多媒体与智能软件技术实验室、北京工业大学北京市多媒体与智能软件技术实验室、北京市交通信息中心、北京工业大学北京市多媒体与智能软件技术实验室、北京市交通信息中心、北京市交通运行监测调度中心 |
| 更多格式 | 高清、无水印(增值服务) |



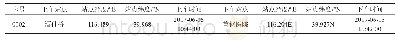


{kind=link}