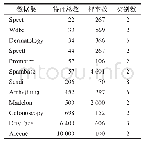
《表6 算法比较序值表:利用一致性分析的高维类别不平衡数据特征选择》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
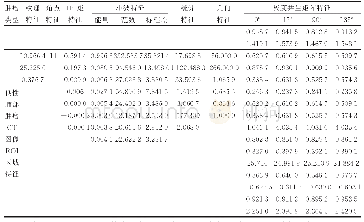
序值表6中的子表(a)-(c)分别根据表3-表5的测试结果给出了多数据集多算法在F-Score、G-Mean和分类精度评价指标上的算法比较序值表,各算法在每个数据集上根据测试性能由好到坏排序,并赋予序值,若算法的测试性能相同,则平分序值.表6横轴的数字对应表3的表头横轴代表的算法,纵轴的数字对应表3的表头纵轴代表的数据集,其中,最后一行表示各算法的平均序值.对表F检验参数alpha取0.05的常用临界值表可知,8个算法12个数据集的临界值为2.131,根据Friedman统计量公式,计算F-Score、G-Mean、分类精度的τF值分别为7.934、6.998、9.299,均大于F检验临界值2.131,拒绝“所有算法性能相同”的假设,进行Nemenyi后续检验.对表Nemenyi检验参数alpha取0.05的常用qα值表可知,8个比较算法的qα值为3.031,根据Nemenyi检验的临界值域公式,计算得到临界值域CD为3.031.
| 图表编号 | XD00157818300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.01 |
| 作者 | 陈祥焰 |
| 绘制单位 | 闽南师范大学计算机学院、数据科学与智能应用福建省高等学校重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}