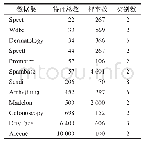
《表1 实验数据集:针对高维数据的马尔科夫毯特征选择》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在表1中,选择了UCI的12个基准数据集,其中有5个机器学习数据集存储库(Spect、Wdbc、Spectf、Promoter、Spambase)、4个生物医学数据集(Colonoscopy、Scadi、Arrhythmia、Dermatology)、2个2003NIPS特征选择挑战数据集(Madelon、arcene)和1个图像处理数据集(Driv Face)。这12个数据集涵盖了广泛的实际应用,包括临床成像、基因表达、生态学和分子生物学。12个数据集的维度从22到10 000、样本大小从70到数千、数据集的类别从2到16,代表性广泛。对表1中的每个数据集,随机选取50%的实例作为所有实验应用的训练数据集,其余50%的实例作为测试数据集。利用训练数据通过各种特征选择方法来选择最优的特征子集。然后将所选择的最优特征子集应用于测试数据。
| 图表编号 | XD00201603200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.15 |
| 作者 | 李静星、杨有龙 |
| 绘制单位 | 西安电子科技大学数学与统计学院、西安电子科技大学数学与统计学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}