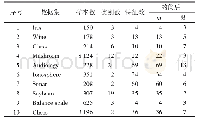
《表1 实验所用高维数据集》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
其中,nl表示集群Cl的样本数目,n'h表示第h类的样本数目,nl,h表示集群Cl和第h类交集的样本数目。从定义可以看出,归一化互信息NMI的取值范围是0到1,该指标是衡量两个集群相似度,数值越大则表示两个集群越相似。本文的所有实验都由Matlab R2014a编写运行,运行计算机处理器是1.80 GHz Intel CoreTMi5-3337U,内存为8 GB。为了公平比较,文中提出的非参核学习算法正则参数α=0.2,k近邻方法的参数k=5,且成对相似约束和不相似约束的数目相等,与Baghshah文献[9]的参数设置相同。本节实验所采用的数据集如表1所示,其中n表示数据集中数据的个数,d表示数据的属性数目,c表示数据集的所分类别数目。
| 图表编号 | XD0035456200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.01 |
| 作者 | 杨烁、刘兵、周勇 |
| 绘制单位 | 中国矿业大学计算机科学与技术学院、中国矿业大学计算机科学与技术学院、中国矿业大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}