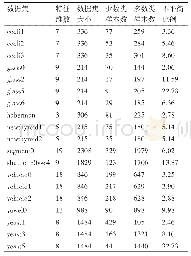
《表1 实验中所用数据集的基本信息》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
数据集.我们采用8个数据集,其中包含2个合成数据集,CIR500G和SIN500G;以及6个真实数据集,Luxembourg,Weather,Gas Sensor,Powersupply,Electricity,Covertype.表1展示了所使用数据集的基本信息,包括数据集名称、样本数目、维度和类别数目.CIR500G合成数据集是CIRCLE数据集[17]的变种,数据属性为2维,决策边界为圆形,并通过调整圆的半径模拟分布变化.具体而言,数据决策空间为x12+x22 r,其中r={3,2.5,2,2.5,3,3.5,4,3.5},变化周期为500.SIN500G合成数据集是SINE数据集[17]的变种,数据属性为2维,决策边界为正弦函数,并通过调整j角度模拟分布变化.具体而言,数据决策空间为sin(x1+θ) x2,其中θ0=0,?θ=π/60,变化周期为500.实验中所用到的真实数据集包含文本、气象、电费、森林覆盖率等多方面,样本数目规模从1900到最多的58万多,且包含二分类和多分类不同任务.详细的介绍可以参考文献[26]的附录1.
| 图表编号 | XD00204794400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.20 |
| 作者 | 赵鹏、周志华 |
| 绘制单位 | 南京大学计算机软件新技术国家重点实验室、南京大学计算机软件新技术国家重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |
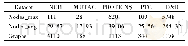



{kind=link}