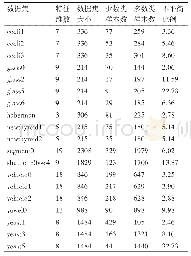
《表1 七个真实数据集的基本信息》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
模拟数据集主要由LFR[15]基准图组成。选择不同的参数生成不同的LFR基准图,不同的参数生成不同类型的复杂网络。N表示网络节点数目,k珋为网络中节点的平均度数,kmax是指网络中最大度数,u表示可调的模糊参数(混合参数),On与Om分别是指重叠节点数目和重叠节点社区从属数目,τ1表示节点度的幂率分布系数,τ2为社区规模的幂率分布系统,cmin与cmax分别是指网络中社区的最小规模和最大规模。当LFR基准网络参数设定为N=5000,τ1=2,τ2=1,k珋=10,kmax=50,设置混合参数为μ=0.3,它是指在同一个社区内一个节点与其他节点的链接率;网络中社区规模设置为(20,100);重叠节点个数On设置为占网络所有节点的10%;重复节点所属社区的个数Om设置为2、3、4、5、6,Om值越大,划分重叠社区结构的难度越大。真实数据集的基本信息[15]如表1所示。
| 图表编号 | XD0067687900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.01 |
| 作者 | 楚杨杰、杨忠保、洪叶 |
| 绘制单位 | 武汉理工大学理学院、武汉理工大学理学院、武汉理工大学理学院 |
| 更多格式 | 高清、无水印(增值服务) |


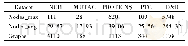

{kind=link}