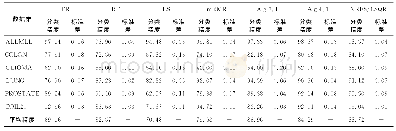
《表7 两种算法对数据集soybean特征选择的实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于EK-medoids聚类和邻域距离的特征选择方法》
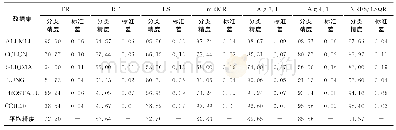
由表5~7的实验结果分析可知,在经过算法2的特征选择后重新聚类的各项指标与文献[10]所提出的算法1进行特征选择后重新聚类的各项指标对比,算法2在表5和6中召回率的标准差略低于文献[10]所提出的算法1,在表7中的召回率的最大值和表7中类精度的标准差略低于文献[10]所提出的算法1。其主要原因是由于所选特征子集的结构特性而导致的。算法2的其他指标的实验结果均明显优于文献[10]所提出的算法1。表5~7的实验结果说明了两种特征选择算法再重新聚类时,本文所提出的算法2的各项指标均优于文献[10]所提出的算法1,从而反映出算法2所选的特征子集在分类精度和正确率方面均高于文献[10]所提出的算法1。这些实验结果充分表明本文所提出的基于EK-medoids聚类和邻域距离的特征选择算法不仅可以有效提高聚类算法的精度,还可以选择出分类精度较高的特征子集,从而验证了本文所提出的聚类优化特征选择算法的有效性和适用性。
| 图表编号 | XD0090301600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.01 |
| 作者 | 孙印杰、张新乐、孙林 |
| 绘制单位 | 河南师范大学计算机与信息工程学院、河南师范大学计算机与信息工程学院、河南师范大学计算机与信息工程学院、河南师范大学河南省高校计算智能与数据挖掘工程技术研究中心 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}