《表2 实验结果比较:一种新的近邻密度SVM不平衡数据集分类算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
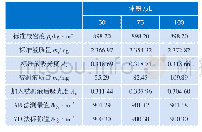
为验证本文算法的可行性,用Matlab2014a编写程序,选人工数据集Dataset和UCI数据集为实验对象,将测试结果与文献[9]主动学习SMOTE的非均衡数据分类(Active learning SMOTE Support Vector Machine,ALSMOTE-SVM)算法、文献[12]中WSVM算法和SVM算法比较。图2所示Dataset是密度不均匀的人工数据集,包含1018个数据点。从UCI库中选取不平衡率较轻Iris、Glass Identification数据集和不平衡率较高Spectf Heart、Ecoli数据集进行实验,如表1所示。SVM分类器参数设置:选取高斯函数为核函数,核宽度=1,惩罚因子C=1000,初始α=0.2,实验迭代运行20次,4种算法在5个数据集上运行得到G-mean、F-measure结果如表2所示。在人工数据集Dataset、Glass Identification和Spectf Heart上运行4种算法,得AUC变化曲线如图3所示。
| 图表编号 | XD0063096900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 刘悦婷、孙伟刚、张发菊 |
| 绘制单位 | 兰州文理学院传媒工程学院、兰州文理学院传媒工程学院、兰州文理学院传媒工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}