《表1 权重矩阵:一种基于权重矩阵的协同过滤算法的相似度度量方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
针对评分矩阵的数据没有完整的标准,在改进相似度的计算过程中,将矩阵中的数据改为完全通过计算得来的数据,一方面减少了用户在消费过程中额外评分的操作,另一方面可以将数据进一步精确化,如表1所示。权重矩阵可以用一个m×n的矩阵w(m,n)来表示,其中m行表示有m个用户,n列表示有n个可访问项目,w(i,j)表示用户i对项目j的权重。
| 图表编号 | XD00112646500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.15 |
| 作者 | 周满满、袁凌云 |
| 绘制单位 | 云南师范大学民族教育信息化教育部重点实验室、云南师范大学信息学院 |
| 更多格式 | 高清、无水印(增值服务) |

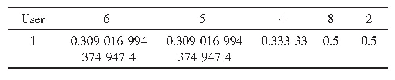



{kind=link}