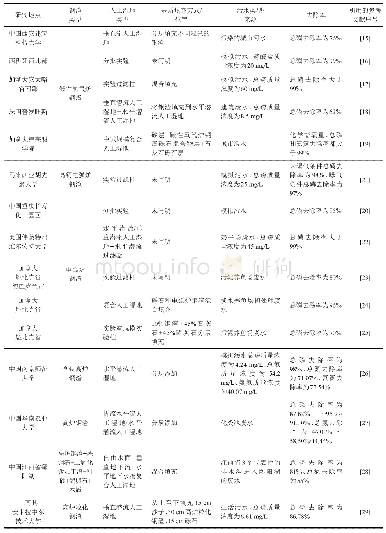
《表1 合成生物学DBTL各环节中人工智能的应用情况》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在以上的案例中我们看到在实现合成生物学的DBTL的每一个环节都涉及大量的数据,而且这些数据形成的变量空间非常大,靠传统的基于小样本的统计推断方法已经无法满足要求,也严重限制了知识获取及再利用的效率。这也就给依赖于大量数据的机器学习尤其是深度学习发展应用的空间,表1总结了近些年来在Design、Build、Test、Learn的各个环节中机器学习的应用情况。为了实现工程生物学真正成为推动生物经济学发展的原动力,美国工程生物学联盟结合80位领域专家的意见,经过多轮研讨于2019年6月制定的工程生物学路线图中重点指出,未来发展基于多组学数据和机器学习的DBTL循环支持系统是关键环节[13]。要实现这一目标,需要满足一些先决条件,即用于机器学习的数据需满足:找得到(findable)、可获取(accessible)、能共通(interoperable)、可重用(reusable)即FAIR原则。要获取关于FAIR原则的更多信息可以参考Wilkinson等[14]的文章。
| 图表编号 | XD00137906900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.01 |
| 作者 | 夏建业、田锡炜、刘娟、庄英萍 |
| 绘制单位 | 华东理工大学生物反应器工程国家重点实验室、华东理工大学生物反应器工程国家重点实验室、武汉大学计算机学院、华东理工大学生物反应器工程国家重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



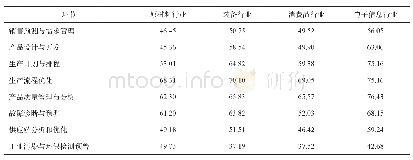
![表1:对比两组药物配置过程中各环节差错发生情况[组(%)]](http://bookimg.mtoou.info/tubiao/gif/ZGCF202009019_00500.gif)
{kind=link}