《表4 数据筛选结果:基于最大熵模型预测东北地区红松潜在分布》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
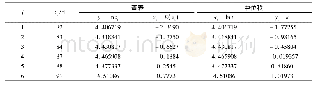
数据的相关性会影响模型的准确性和预测结果。一般来说,变量之间相对独立是统计建模的前提,所以需要进行数据的筛选,使得数据之间的相关性最小,但是所保留的数据又有一定的代表性。本研究中通过相关系数选取变量。不同环境变量之间的相关系数如表3所示,如果两个变量因子之间的系数大于0.9,则将其中一个剔除。选择后,环境变量的数量减少了一半,筛选前后数据情况如表4所示。
| 图表编号 | XD00134776900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.20 |
| 作者 | 张劳模、庞丽峰、许等平、唐小明 |
| 绘制单位 | 中国林业科学研究院资源信息研究所、河南工程学院计算机学院、中国林业科学研究院资源信息研究所、国家林业局林产工业规划设计院、中国林业科学研究院资源信息研究所 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}