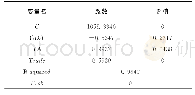
《表2 非平衡数据抽样处理》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:挂号内为该类别所占总计的百分比。
数据挖掘技术中解决分类问题的模型众多,经典的分类算法有朴素贝叶斯、K-近邻算法、决策树等。在集成学习的框架下,通过多个弱分类器的组合优化可得到强分类器,根据弱分类器间是否有依赖关系,可分为Bagging算法和Boosting算法,前者存在强依赖关系,其中较经典的拓展就是随机森林模型;后者的弱分类器间是串行关系,典型算法是Xgboost分类。以是否参与过众筹作为二分类响应变量,根据构造的4个新数据集分别构建决策树、随机森林、Xgboost和支持向量机模型,以特异性、敏感度、准确率、AUC曲线等量化指标作为调节参数,并用来评价分类器性能。
| 图表编号 | XD00132988700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.20 |
| 作者 | 顾洲一、邱瑾 |
| 绘制单位 | 浙江金融职业学院、浙江财经大学 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}