《表4 不同分类器对应的评估指标》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
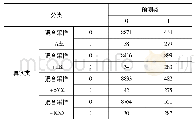
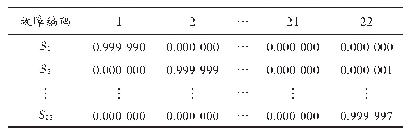
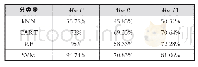
本实验采用基于随机混合采样和遗传算法的集成分类方法,其中分类器为XGBoost,交叉验证为5折,迭代次数是1 000.混合采样中,z值取2.遗传算法中,依次选用3~20个最优个体,多次实验发现最优个体数为9,即最后得到的最优特征子集为9个.实验结果如表4所示,从结果中可以看出,基于随机混合采样与遗传算法的分类器分类效果最佳,准确率与XGBoost算法相比提高了19.25%,说明了算法的有效性,通过随机采样与遗传迭代,能够获得平衡且特征数较少的数据集,从而提高分类器性能.表5为2007年垃圾网页挑战赛中优胜团队的结果,可以看出,在F1值这个评价指标上笔者提出的算法是优于其他队伍的,但是在AUC这个指标上较低,然而AUC值最高的Cormack团队的F1值仅为0.67,说明其分类效果并不好.
| 图表编号 | XD00129612000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 刘寒 |
| 绘制单位 | 北京邮电大学软件学院、北京邮电大学可信分布式计算与服务教育部重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}