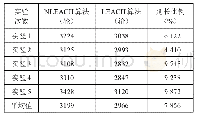
《表2 两种算法的实验结果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
基于上述改进的风险短语识别算法对全部6257条风险描述文本进行风险短语抽取,设定阈值挑选共现概率高的候选词串(即互信息值高的词串),通过互信息值挑选出共现概率高的词,再选取左右熵值之和最高的前20个词,降序输出,过滤数字等无意义短语以及长度小于4的噪声词,最终获得7551个风险短语。对于同样数据,进行基于HanLP的短语识别,最终获得58488个短语。以第4.2节中的前10个文本为例,两种算法的抽取结果如表2所示。
| 图表编号 | XD00121820300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.24 |
| 作者 | 梁娜、姚长青、王峥、高影繁、李岩 |
| 绘制单位 | 中国科学技术信息研究所、中国科学技术信息研究所、中国科学院文献情报中心、中国科学技术信息研究所、中国科学技术信息研究所 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}