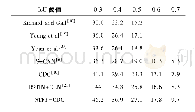
《表3 本文算法与其他算法在单流及双流上的识别率比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于SDBN和BLSTM注意力融合的端到端视听双模态语音识别》
本文算法在5个不同角度的单流唇部视频、音频及其双流融合后的结果见表3(A表示纯音频实验,A+0°表示两者融合实验)。对于单流模型实验,音频的识别率最高,优于所有角度的唇部视频识别结果,这是因为音频承载了绝大部分的信息。5个角度唇部视频中以正面录制的视频包含最多信息,识别率最高。在视听融合实验中,将提出的算法与当前标杆算法[22,23]进行了比较,可以看到即使单流音频结果与其接近,但音频分别与0°、30°、45°、60°、90°唇部视频进行注意力融合后的识别率均优于当前标杆算法,其中音频与正面唇部视频的融合实验中识别率高达0.991。这一实验结果也与热力图所得结果相符,证实提出的视听融合识别模型的有效性。同时在图7中,画出了在测试集上各受试者在10次重复训练实验中单流0°唇部视频、音频及两者融合的双流实验的分类准确率,可以观察到单流实验而言,音频流识别率均优于0°唇部视频,其中9号与30号受试者的语音识别达到100%。同时,除了30号,所有受试者进行注意力融合后的双模态视听语音识别结果均优于单流模型识别结果,而且融合后的结果均高于95%,其中9号、34号和44号受试者融合实验分类率达到100%。
| 图表编号 | XD00116371100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.20 |
| 作者 | 王一鸣、陈恳、萨阿卜杜萨拉木·艾海提拉木 |
| 绘制单位 | 宁波大学信息科学与工程学院、宁波大学信息科学与工程学院、宁波大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}