《表2 增加样本前后测试准确度对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
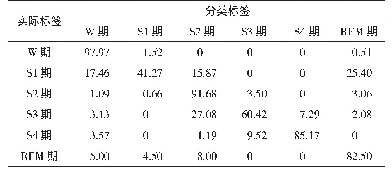
由于训练集对模型识别的结果影响较大,特地在原有样本基础上,新增王羲之书法字体和颜体书法字体,通过字体生成技术生成单字160个不同的样本,见图7。同样进行20轮迭代训练后,得出的测试结果如表2所示。可见,增加字体样本后未识别样本降低,整体的准确率有所提升。所以,训练样本字体的多样性有助于提升CNN网络的识别率。可以通过将古籍中的汉字切割、标注、预处理后构建训练样本,以此提高样本的多样性,进而提升识别性能。
| 图表编号 | XD00106779800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.10 |
| 作者 | 郭利敏、葛亮、刘悦如 |
| 绘制单位 | 同济大学图书馆 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}