《表1 各数据集的基本特征》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
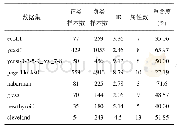
本文改进的算法,通过Python语言编写,用Spyder工具对实验结果进行显示.为了验证算法的有效性,本文选取4组人造数据和7组不同UCI数据库数据集进行实验,通过与CFSFDP算法、文献[14]改进过的IDPCA算法、DBSCAN算法和K-means算法进行对比,以验证本文算法的性能.各数据的特征如表1所示,其中,Aggregation、Jain和Three cluster是人造数据;Iris,Wine,Seeds,Ionosphere,WDBC,waveform3和CM C是UCI数据库中的真实数据.
| 图表编号 | XD009528600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 赵燕伟、朱芬、桂方志、任设东、谢智伟、徐晨 |
| 绘制单位 | 浙江工业大学特种装备制造与先进加工技术教育部浙江省重点实验室、浙江工业大学特种装备制造与先进加工技术教育部浙江省重点实验室、浙江工业大学特种装备制造与先进加工技术教育部浙江省重点实验室、浙江工业大学计算机科学与技术学院、浙江工业大学特种装备制造与先进加工技术教育部浙江省重点实验室、浙江工业大学特种装备制造与先进加工技术教育部浙江省重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |
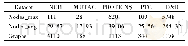




{kind=link}