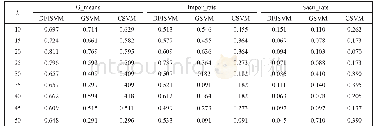
《表2 Quora语料上实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
(注:“开发集”和“测试集”两列对应的单位为“%”)
模型在开发集与测试集上的准确率如表2所示。其中前4行数据取自BiMPM的工作;MatchPyramid模型性能是利用MatchZoo[19]复现得到;第6行至第7行的数据取自DECATT[2]的工作,Pt-DECATTword与Pt-DECATTchar是引入外部数据Paralex[20]语料作为噪声数据进行预训练得到。PtDECATT将3 600万的Paralex语料做为正样本,构造将近6 400万负样本,整个预训练噪声数据规模将近1亿。
| 图表编号 | XD0091826800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 陈鑫、李伟康、洪宇、周夏冰、张民 |
| 绘制单位 | 苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}