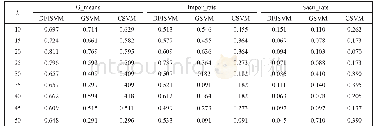
《表1 KITTI数据集上实验结果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
如表1所示,本文采用KITTI数据集进行了5组对比实验,前2组分别为文献[12]、文献[15]提出的基于监督学习的单目深度估计,第3组和第4组分别为文献[19]、文献[20]提出的无监督学习的单目深度估计(输入图像未进行金字塔处理且训练损失函数比较单一),第5组为本文模型采用VGG-16进行特征提取的无监督学习的单目深度估计。根据表中的数据可以得出以下结论:1)本文模型进行深度估计的准确率接近甚至优于基于监督学习的单目深度估计模型,这说明基于无监督进行深度估计具有较高的可行性;2)第3组、第4组和第5组数据表明,图像金字塔处理可以实现不同大小目标的检测,进而提高深度估计的准确率,联合视差图平滑性损失、图像重构损失、视差图一致性损失作为训练的总损失有助于提升模型的训练效果,进而提升深度估计的准确率;3)第5组和本文模型对比得出基于ResNet-50进行特征提取可以降低模型的训练损失,进而提高深度估计的准确率,综上可以得出,本模型提出采用ResNet-50进行特征提取、联合视差图平滑性损失、图像重构损失、视差图一致性损失作为训练的总损失函数有助于提升深度估计的准确率;4)本模型每一帧图片的检测时间少于其他模型,平均每帧图片检测时间为0.048s,即每秒检测21frame,本无人机平台选用的单目相机每秒拍摄20frame,因此本模型满足无人机自主飞行中实时深度估计的要求。
| 图表编号 | XD00133387600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.25 |
| 作者 | 赵栓峰、黄涛、许倩、耿龙龙 |
| 绘制单位 | 西安科技大学机械工程学院、西安科技大学机械工程学院、西安科技大学机械工程学院、西安科技大学机械工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}