《表9 两种算法在Skin数据集上实验结果的对比(单位:s)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《MapReduce和Spark两种框架下的大数据极限学习机比较研究》
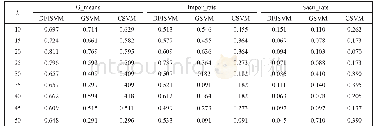
对比情况,结果显示:基于Spark平台的ELM算法的speed Up值总体高于基于MapReduce平台的ELM算法的speed Up值,随着隐层节点数的增多,这种差异更加突出.speed Up折线图近似于一条直线,且斜率有减小的趋势这是因为并行计算将不可避免的增加在不同机器上的数据交换,造成时间的浪费.图4是隐层节点分别是10、20、30,训练数据集分别是原始数据集的5倍、8倍、10倍.由图4可知,基于Spark平台的ELM算法的sizeUp值总体低于基于MapReduce平台的ELM算法sizeUp值,也就是说,训练的数据集规模越大时,Spark平台上数据处理效率越突出.这是因为Spark是一种基于内存计算的大数据平台,中间结果可以缓存至内存中,且只有RDD的行动算子才会触发计算,相较于MapReduce平台,不存在中间数据流动至HDFS的情况,数据IO操作较少,但在MapReduce平台上随着隐层节点增多时,在算法执行过程中会存在更大规模的矩阵运算,这将导致更大规模的数据IO操作,造成严重耗时.
| 图表编号 | XD00175973300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.01 |
| 作者 | 宋丹丹、翟俊海、李艳、齐家兴 |
| 绘制单位 | 河北大学数学与信息科学学院、河北大学数学与信息科学学院、河北大学河北省机器学习与计算智能重点实验室、河北大学数学与信息科学学院、河北大学河北省机器学习与计算智能重点实验室、河北大学数学与信息科学学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}