《表1 0 两种算法在covertype数据集上实验结果的对比(单位:s)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《MapReduce和Spark两种框架下的大数据极限学习机比较研究》
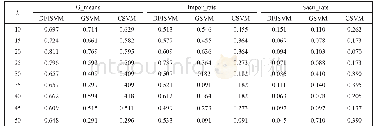
Spark是一种用于内存计算的大数据处理框架.它的设计理念中最重要的一点是改善大数据并行运算时网络数据流量承载过重和磁盘I/O开销过大的问题.在Spark中,弹性分布式数据集RDD(Resilient Distributed Dataset)是最重要的组成成分之一.RDD是一个抽象的数据结构,待处理的数据均被高度抽象至RDD中.从物理层面上分析,RDD将待处理的数据散布在集群的各个节点上,存储于内存或外存上,通过唯一的标识符对其进行操作;从逻辑层面上分析,待处理的数据块根据实际操作划分分区数.RDD通过算子操作分区,完成转换或行动操作,形成新的RDD.在Spark平台上的一切操作都是对RDD的操作.这些操作统分成两大类,被称为Transformation(转换)操作和Action(行动)操作.RDD中所有的转换操作都不会直接计算结果,都是延迟加载的操作.它们只是记住这些应用到基础的数据集(例如一个文件)上的转换操作.只有当发生一个要求返回给Driver的动作时,这些转换操作才会真正运行,这种设计使Spark更加有效率.M apReduce和Spark的差异性如表1所示.
| 图表编号 | XD00175973700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.01 |
| 作者 | 宋丹丹、翟俊海、李艳、齐家兴 |
| 绘制单位 | 河北大学数学与信息科学学院、河北大学数学与信息科学学院、河北大学河北省机器学习与计算智能重点实验室、河北大学数学与信息科学学院、河北大学河北省机器学习与计算智能重点实验室、河北大学数学与信息科学学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}