《表2 数据集输入句子形式》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
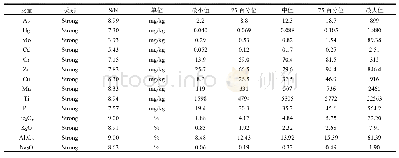
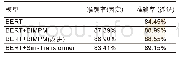
实验时随机选择训练数据中90%的数据作为训练集,剩下10%作为开发集。所有的数据在输入前需要经过预处理,将中文习语替换成*,英文单词替换成&,数字替换成$,在大规模的无标注的语料上进行字向量训练,将训练完成的字向量作为本次实验的词向量。将每个数据集的输入语句都添加各自的标志符,不同数据集带有标志符的句子形式示例如表2所示。当计算最终输出的分值时不计算标志符。为了便于评估,本文使用标准bake-off打分程序来计算准确率P、召回率R、F1分值。
| 图表编号 | XD0090317700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 章登义、胡思、徐爱萍 |
| 绘制单位 | 武汉大学计算机学院、武汉大学计算机学院、武汉大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}