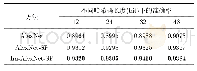
《表3 不同方法下准确率比较(五次计算取平均值)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文采用经典的K-means聚类算法,以准确度F1值为评价指标来衡量文本相似度计算效果。在效果对比时,本文采用传统TF-IDF方法、经典LDA方法与本文提出的WMF_LDA模型进行比较,并将本文提出的基于语义的词语合并与基于词性的词语筛选(word merging and filtering,WMF)与传统TF-IDF相结合,一并作为对比实验。实验结果如表3所示。
| 图表编号 | XD0090317600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 张璐、芦天亮、杜彦辉 |
| 绘制单位 | 中国人民公安大学信息技术与网络安全学院、中国人民公安大学信息技术与网络安全学院、中国人民公安大学网络空间安全与法治协同创新中心、中国人民公安大学信息技术与网络安全学院、中国人民公安大学网络空间安全与法治协同创新中心 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}