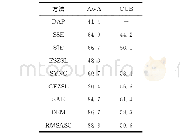
《表2 零样本分类准确率比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:语义属性,v代表VGG提取的视觉特征,g代表GoogLetNet提取的视觉特征。
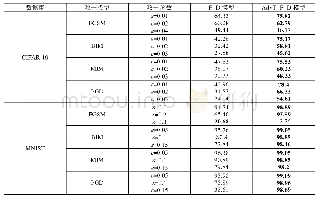
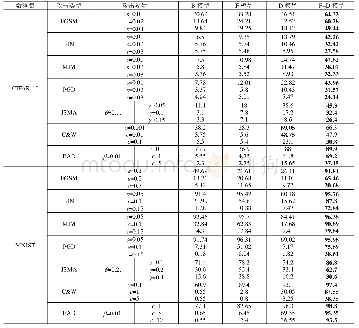
在本部分实验中,分别采用语义属性和词向量作为语义特征,将本文提出方法在Aw A和CUB数据集上进行零样本分类准确率实验,并将分类结果同其他方法进行比较。(1)采用语义属性作为语义特征的实验结果如表2所示。从实验结果可以看出,本文提出的方法在AwA和CUB数据集上取得较为显著的效果,其中,在AwA上除了比JLSE算法低1.3%外,均优于其他对比算法。在CUB数据集上效果更加明显,达到54.1%的分类准确率。(2)采用词向量作为语义特征的实验结果如表3所示。实验结果表明,本文提出的方法在两个数据集上均优于对比算法,具体表现为:在AwA数据集上,本文提出的算法与SynC[5]、CCA[18]、SJE[6]和LatEm[7]相比较,分别提高了7.1%、3.4%、13.4%和3.5%。在CUB数据集上分类准确度达到34.1%,比效果较好的LatEm[7]算法高2.3%。另外,通过对比表2和表3的实验结果,相比于词向量,语义属性作为语义特征的分类效果会更高,主要原因是语义属性是由人工进行属性标注,具有更充足的视觉描述信息,而词向量仅由上下文关系得,反映的是词语间的共现关系。
| 图表编号 | XD0090173200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.01 |
| 作者 | 马丽红、谭学仕 |
| 绘制单位 | 华南理工大学电子与信息学院、华南理工大学电子与信息学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}