《表1 识别率比较:水下目标多模态深度学习分类识别研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
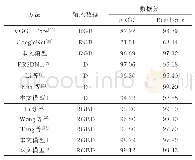
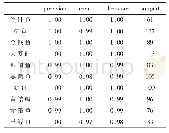
将多模态深度学习模型与SVM、CNN以及LSTM网络识别方法进行分类识别率比较。其中SVM采用高斯核函数,惩罚因子C的选择依赖于多次试验,惩罚因子越大,表示分类方法不能容忍出现误差,但是容易出现过拟合,当惩罚因子越小时,表示分类模型对误差的宽容度较强,但容易出现欠拟合,经过多次优化测试,选择惩罚因子为67.3,训练步数设置为200。CNN设置两层卷积层,一层池化层和一层全连接层。激活函数为ReLU,两层卷积层的节点数分别设置为16和32,卷积核大小分别为5*5和3*3,池化层卷积核大小为3*3,一层全连接层,采用Softmax输出层,输出节点为5,学习率设置为10×10-5,epoch为10000步,迭代直到达到设定阈值。LSTM网络参数中,一维信号进行输入时首先进行归一化处理,动量因子设置0.95,衰减因子设为0.1,初始门控设置为0,采用L1正则化方法,激活函数为sigmoid,学习速率设置为0.01,输入向量维度为2,隐含层维度为32,输出层维度为1,迭代10000步。多模态深度学习模型的两种模态输入参数设置与上述一致,CCA特征融合时初始迭代因子设置为2,参数共享后,对特征向量进行深度自编码分类识别,自编码网络选择堆栈自编码(Stacked auto-encoder,SAE)。采用Tensorflow深度学习框架[18]进行训练。采用英伟达丽台K4200 GPU加速,每个模型训练时间达到6 h。该训练-测试比条件下的结果如表1所示,其中识别率=(测试集中正确分类样本数)/测试集总样本数。
| 图表编号 | XD0081685300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.01 |
| 作者 | 曾赛、杜选民 |
| 绘制单位 | 水声对抗技术重点实验室、上海船舶电子设备研究所、水声对抗技术重点实验室、上海船舶电子设备研究所 |
| 更多格式 | 高清、无水印(增值服务) |

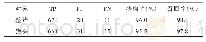


{kind=link}