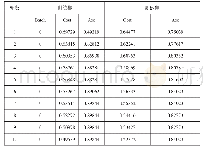
《表2 近似词集部分示例:网络谣言敏感词库的构建研究——以新浪微博谣言为例》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《网络谣言敏感词库的构建研究——以新浪微博谣言为例》
(1)近似词集扩展。利用Word2Vec工具计算得到300个种子词集的词向量,再分别计算各个词向量维度上的均值,计算得到种子词集的均值向量。用词集的平均向量利用KNN模型聚类,得到300个种子词最相近的词。实验中共取到与种子词集同属一类的1 785个词作为扩展的近似词,形成的近似词集如表2所示:
| 图表编号 | XD008125200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.28 |
| 作者 | 夏松、林荣蓉、刘勘 |
| 绘制单位 | 中南财经政法大学信息与安全工程学院、中南财经政法大学信息与安全工程学院、中南财经政法大学信息与安全工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}