《表1 复旦大学分类算法性能》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
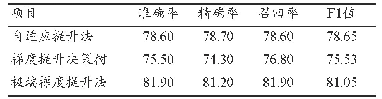
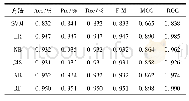
利用之前创建的数据集数据和文本特征可以训练一个分类器,用来判断数据集属于哪种类型的问题.常用的方法有SVM[15-18],KNN,LLSF,NNet等.其中,参考复旦大学自然语言处理实验室使用不同分类算法对基准语料进行测试的结果.这一基准预料共有9804篇训练文档,9833篇测试文档,并分为20类.在经过预处理之后,各个分类方法的性能指标如表1所示.
| 图表编号 | XD0079873900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.01 |
| 作者 | 曾兆伟、曹健 |
| 绘制单位 | 上海交通大学计算机科学与工程系、上海交通大学计算机科学与工程系 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}