《表1 基于Iris dataset的聚类算法结果Tab.1 The Result of Clustering AlgorithmsBased on Iris Dataset》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了验证本文算法聚类效果的优越性,选取了K-means,K-prototype以及MugdhaJain的自适应性K-means算法与本文提出的基于属性值变化程度定权的聚类算法(weighted clustering algorithm based on attribute’s variation,WBAV)进行比较。为便于后续表述,本文实验采用聚类分析中常用的Iris dataset(鸢尾花数据集)作为数据源进行聚类运算。该数据源的样本数为150,簇数为3(Iris Setosa,Iris Versicolor,Iris Virginica),即样本中一共存在3种不同类型的鸢尾花;每个簇(每种鸢尾花)的样本数为50,样本属性维度为4(即萼片的长度、宽度与花瓣的长度、宽度)。研究人员通过自己提出的聚类算法对该数据集中3种花型品种的识别及区分,以检验其算法的有效性及准确度(表1、表2)。
| 图表编号 | XD007917200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.05.20 |
| 作者 | 杨扬、许厚泽、常军 |
| 绘制单位 | 中国科学院测量与地球物理研究所、中国科学院大学、中国科学院测量与地球物理研究所、国家测绘地理信息局第一大地测量队 |
| 更多格式 | 高清、无水印(增值服务) |
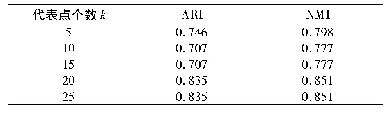
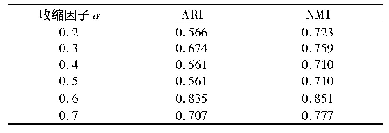




{kind=link}