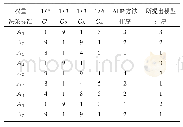
《表1 与其他最新方法相比, 所提出模型的识别精度》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了验证该方法的鲁棒性,采用了低质量的字符中断笔、噪声和缺失部分信息的方法。本文两个相应的低质量字符图像样本,选择真正的劣质传真文本图像的主要特征库中的每个字符,然后相应的平均图像字符减去从低质量的样本中获取的一个错误图像,最后错误图像构造和训练研究遮挡字典。在表1中,给出了与其他最新方法比较的模型识别精度。
| 图表编号 | XD0072466700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.25 |
| 作者 | 县小平、马国俊 |
| 绘制单位 | 甘肃民族师范学院计算机科学系、甘肃民族师范学院计算机科学系 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}