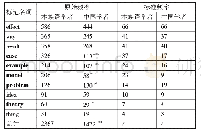
《表1 源端句子的平均长度 (注:以词为单位)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文实验使用的数据集是LDC2017T10。该数据集包含若干英文句子及其对应的AMR图。与相关研究的数据划分一致,训练集、开发集和测试集分别包含36 521个、1 368个句子及1 371个句子和AMR对。为了获取源端句子的句法分析和语义角色标注结果,本文使用开源源代码工具AllenNLP[30](1),该工具的句法分析模型是基于PennTree Bank训练的,语义角色标注模型则是基于英文Ontonotes 5.0训练的。在进行语义角色标注时,工具会识别除了辅助动词和系动词之外的所有谓词的语义角色。融合了句法和语义角色信息之后,不可避免地会增加源端序列的长度。如表1所示,融合源端不同信息后,源端输入序列的平均长度相对于基准模型都明显增加。本文使用SMATCH系统[31]来评估AMR解析模型的性能,该系统会将模型解析生成的AMR图和正确AMR图都转换为三元组,然后进行对比,算出P(精确度)、R(召回率)、F1值。本文实验所使用的代码将在Github上开源公布。
| 图表编号 | XD0070612700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.01 |
| 作者 | 葛东来、李军辉、朱慕华、李寿山、周国栋 |
| 绘制单位 | 苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、阿里巴巴集团、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}