《表1 数据集属性:大数据下的一种挖掘算法的研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文在Apriori算法的基础上,对每一次生成的频繁项集Lk-1(k=1,2,…k-1)添加一个数据库Dk,在数据库Dk中存放k-频繁项集以及其所属的事务集合,设定每一个频繁项集的事务集合为Ei,Ei={t1,t2,…tm,…tq},因此,在由Lk-1进行自连接生成k-候选项集Ck,对Ck进行支持度计算的时候,不需要在对原始的数据库进行扫描,而只需要直接扫描频繁项集数据库中的Ck子集所属于的事务Ei,其次再求出各个子集所属事务的Ei的交集,在这些交集中包含的事务的个数就是该候选项集中的支持数,最后对于小于支持度的若干候选项集进行删除操作,这样能够有效的提高访问效率。算法改进的伪码如表1所示。
| 图表编号 | XD0069204300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.31 |
| 作者 | 谢胡林 |
| 绘制单位 | 绍兴职业技术学院 |
| 更多格式 | 高清、无水印(增值服务) |


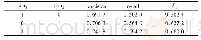


{kind=link}