《表2 各个数据集的特性:一种面对大数据集的改进基于支持向量机的算法性能分析》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《一种面对大数据集的改进基于支持向量机的算法性能分析》
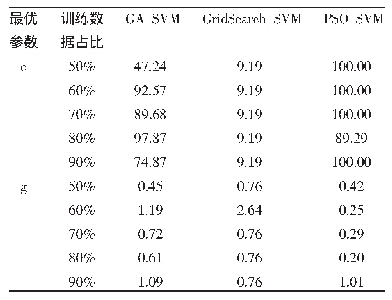
从表2中可以看到分别对三个中等规模数据集进行测试得到的特性。各数据集的惩罚参数C=10,选择高斯径向基函数(σ=0.5)与S形核函数进行处理。总共开展10次随机抽样。相对于子簇上训练得到最优分类器的时间,结合多个分类器的时间可以忽略不计,因此在不同的结合规则下训练时间和测试时间保持不变。算法泛化能力可以利用测试精度进行评价。从表3中可以看到训练集与测试集各自对应的平均分类精度。可以明显发现,采用吸收规则可以达到最高分类精度,使用线性结合规则时得到的分类精度略小,这两者的分类精度都比吸收规则更高。其它核函数也适用相近的结论,此处不再对其具体分析。
| 图表编号 | XD00127014200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.25 |
| 作者 | 江志晃 |
| 绘制单位 | 广东培正学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}