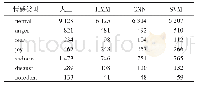
《表3 CART/RF/GBDT三种分类器模型的性能对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于用电特征单一视角数据的中小企业生命周期阶段识别》
本研究优选的分类器模型采用文献[24]详细描述的梯度提升决策树(gradient boosting decision tree,GBDT)集成学习模型,作为对比本文做了随机森林(random forest,RF)模型、分类与回归树(classification and regression tree,CART)模型的识别性能测试,结果见表3所示。训练集为经过SMOTE过采样处理后的309个样本,测试集为原始的212个样本中未被划到训练集而余下的88个样本。其中成长期、成熟期和衰退期企业样本个数分别为70个、12个和6个。值得注意的是,因为衰退期企业样本个数仅为6个,所以为了尽可能逼近真实,本文让这6个样本只参与了SMOTE过采样处理而未参与模型训练。在模型参数调优上,对CART模型的建树最大深度、RF模型的弱学习器个数以及GBDT模型的弱学习器个数和学习率使用了网格搜索调参技巧。在表3中,总体指三个类别的所有样本,失衡类别指的是处于成熟期和衰退期的企业样本。准确率定义为预测对的样本个数除以测试集的88个样本总数。失衡类别的查准率定义为预测对的失衡类别样本个数占预测出的失衡类别样本个数的比率。失衡类别的查全率定义为预测对的失衡类别样本个数占测试集中真实的失衡类别样本个数的比率。
| 图表编号 | XD0067513200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.25 |
| 作者 | 刘同新、杨翠红、房勇、张若兴 |
| 绘制单位 | 中国科学院大学经济与管理学院、普华讯光(北京)科技有限公司、中国科学院大学经济与管理学院、中国科学院数学与系统科学研究院、中国科学院数学与系统科学研究院、普华讯光(北京)科技有限公司 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}